Background and Motivation
Existing MLLMs continue to face challenges related to hallucinations.
Recent attempts have employed human experts or powerful auxiliary AI systems to provide more accurate preference feedback.
However, the responses of MLLMs are usually long, complex and ambiguous with inevitable flaws,
which interferes the preference optimization due to the remaining hallucinations in the preferred responses.
An intuitive alternative is to enhance the quality of preference pairs by directly correcting or contaminating the original responses.
Some approaches rely on extensive human annotations or ultra-large proprietary models
(such as GPT-4V) to detect hallucinations and then rewrite the responses, therefore the scalability of feedback data is still limited.
To address this issue, we propose leveraging the reference model itself to enhance the preference pairs in a self-correctional manner,
without human or proprietary model intervention.

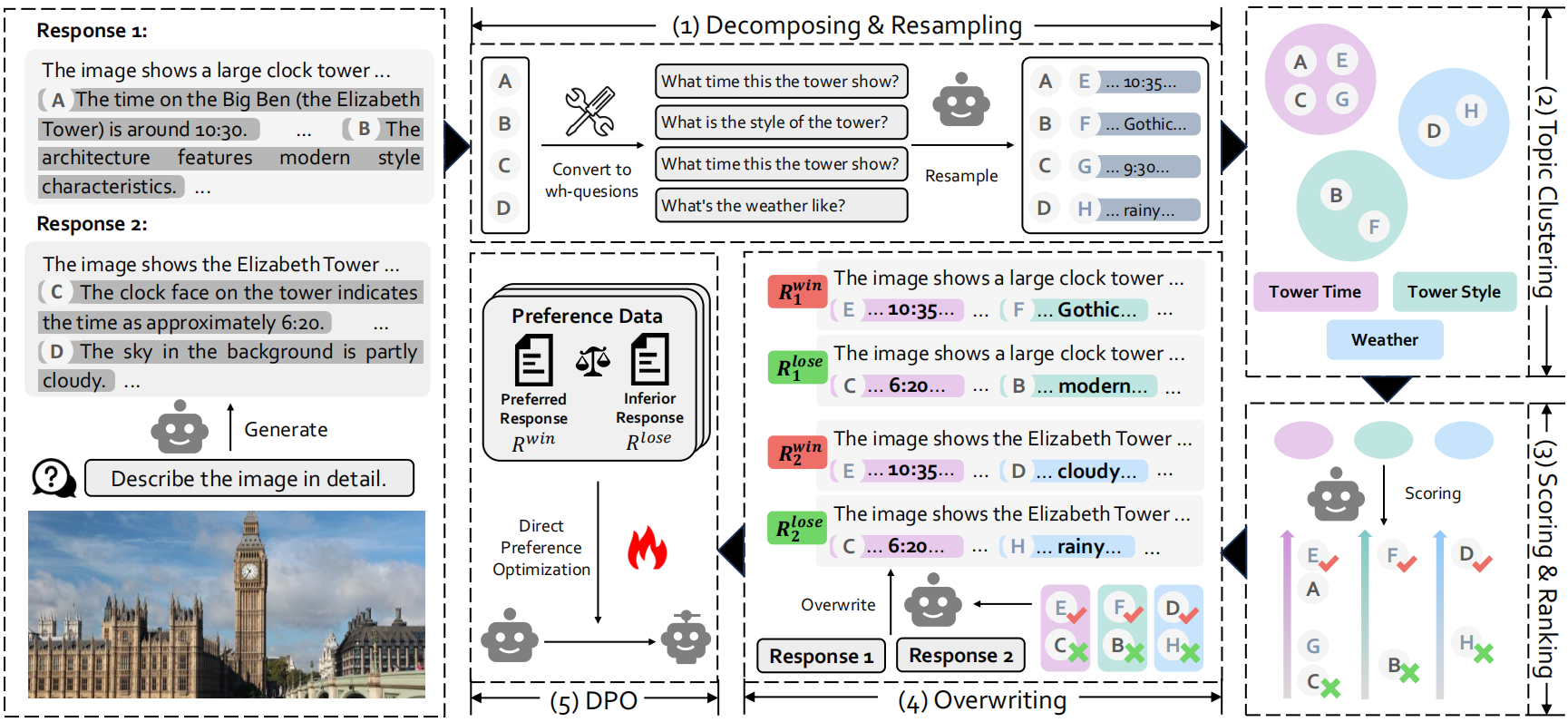
 Topic-level Preference Overwriting
Topic-level Preference Overwriting
We propose a topic-level self-correctional paradigm tailored for reducing hallucinations, Topic-level Preference Overwriting (TPO). We adopt a deconfounded algorithm that replaces all topics involved in a complex response, with the best or worst alternatives resampled multiple times from the reference model itself on the same topic.
📃 Highlights
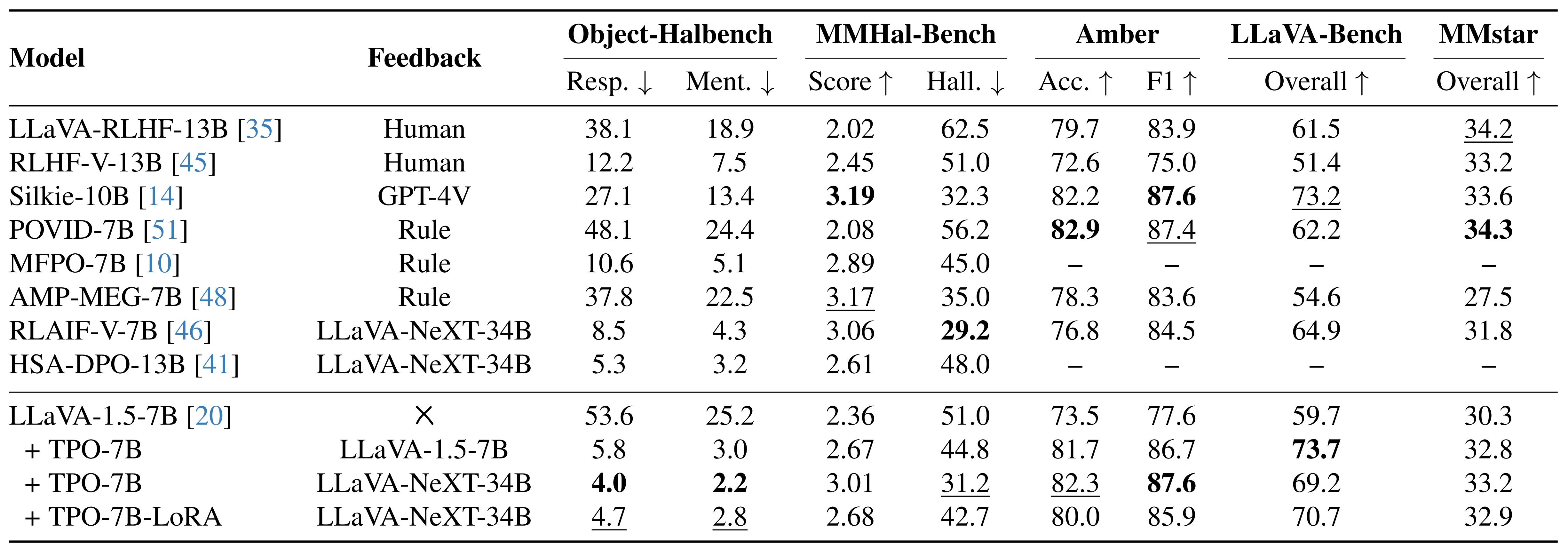
Without bells and whistles, TPO achieves state-of-the-art performance in trustworthiness across several hallucination benchmarks, reducing hallucination of the base model by ~92% on ObjectHal-Bench, and by ~38% on MMHal-Bench. We also align base model with the model itself as labeler, significantly reducing its own hallucinations (by ~88% on ObjectHal-Bench and by ~12% on MMHal-Bench) and breaking through its inherent limitations.
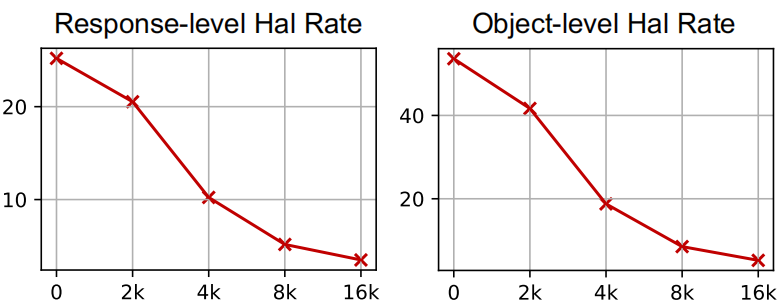
Data Scalability: TPO allows us to collect more feedback data for hallucination reduction at a low cost, without human or proprietary models intervention. As the data scale increases, the trustworthiness of the model continuously improves.
Feedback Quality: We compare the quality of preferred responses generated by TPO with those identified by the labeler model and original responses. We evaluate their informativeness and trustworthiness based on GPT-4V evaluation review. Different colors in the pie charts mark the number of winning responses. TPO outperforms its counterparts in both informativeness and trustworthiness.

🖌 Examples
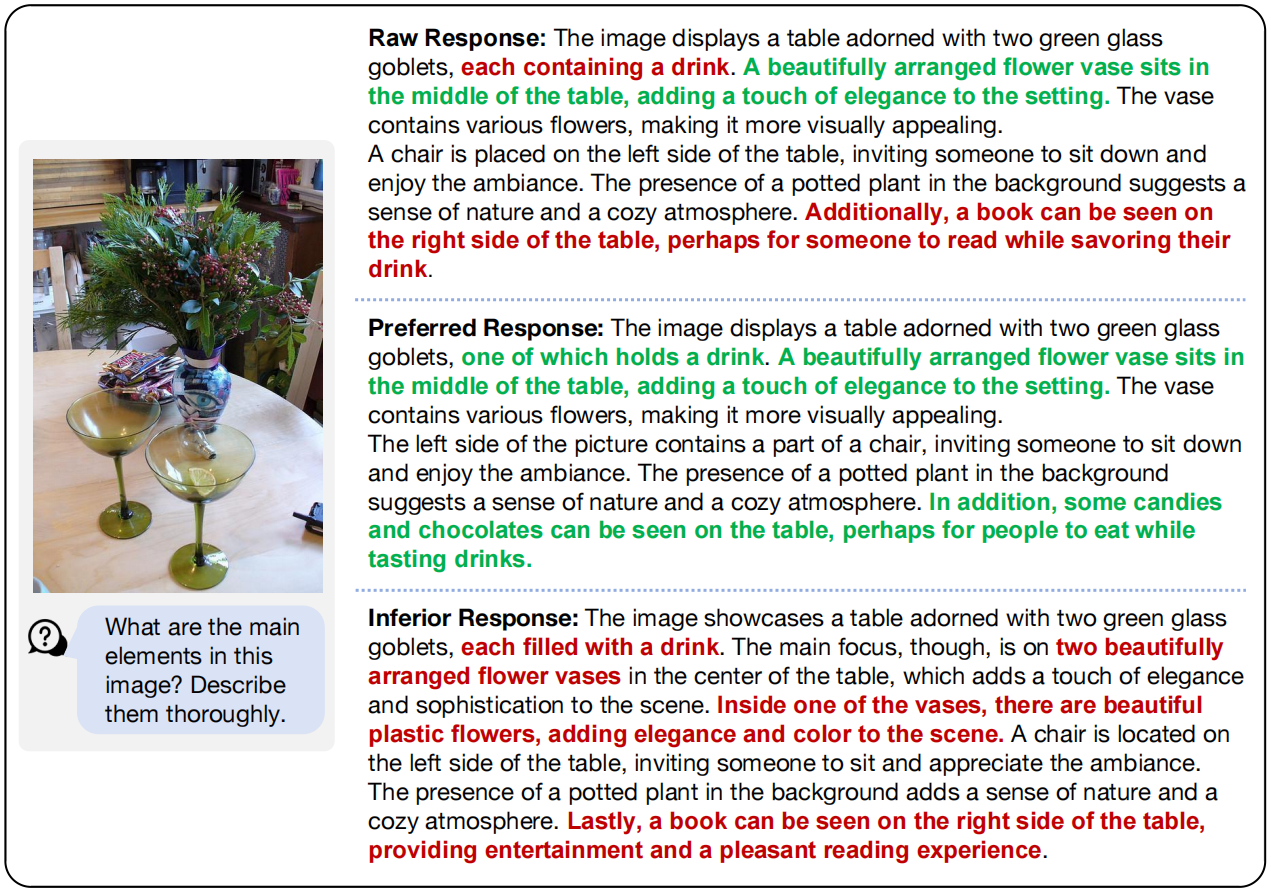
Correct answers and hallucinations are highlighted in color respectively.



BibTeX
@article{he2024topic,
title={A Topic-level Self-Correctional Approach to Mitigate Hallucinations in MLLMs},
author={Lehan He and Zeren Chen and Zhelun Shi and Tianyu Yu and Jing Shao and Lu Sheng},
journal={arXiv preprint arXiv:2411.17265},
year={2024}
}